 6 months ago
41
6 months ago
41

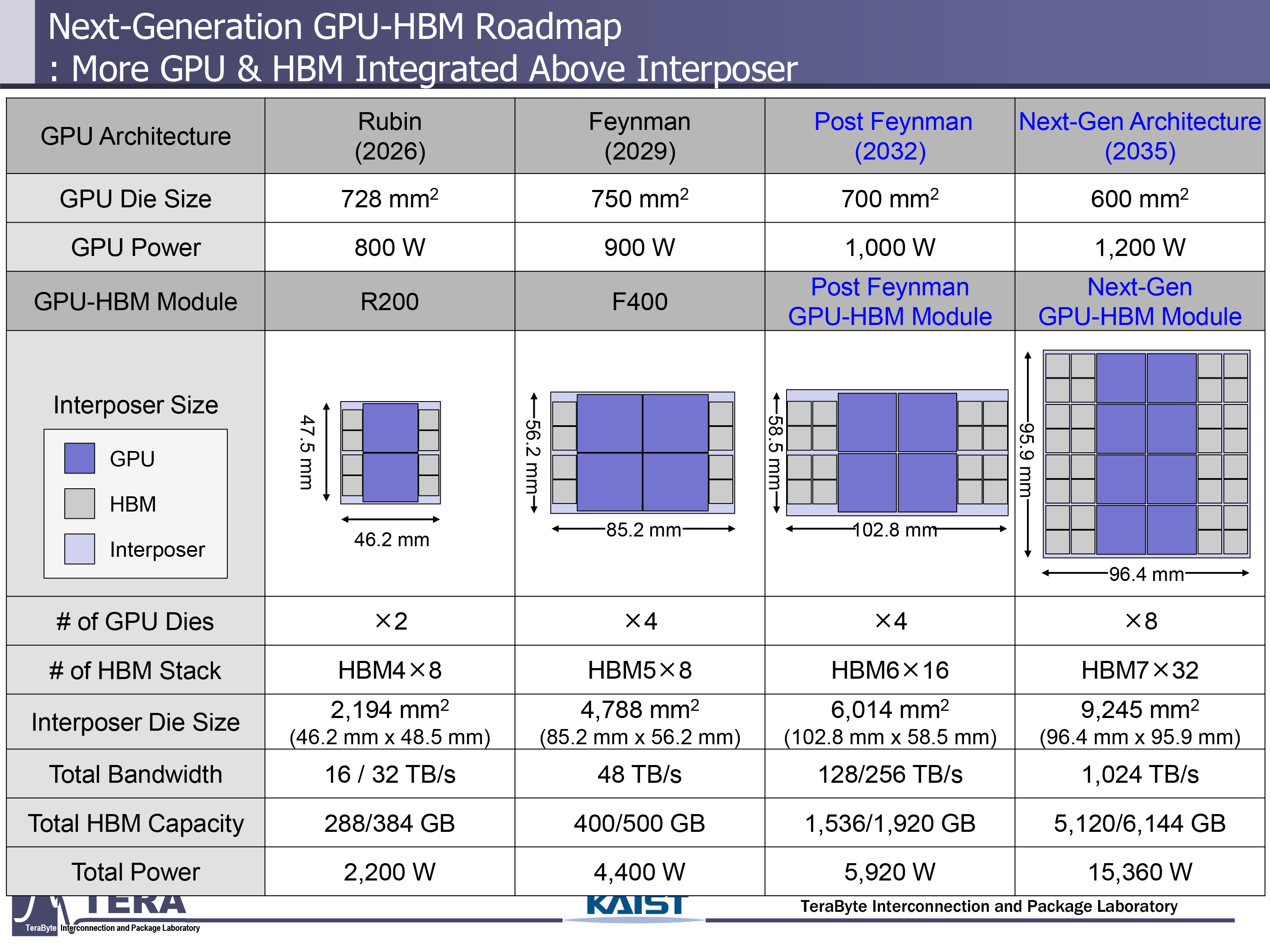
The power consumption of AI GPUs has steadily increased in recent years and is expected to continue rising as AI processors incorporate more compute and HBM chiplets. Some of our sources in the industry have indicated that Nvidia is looking at 6,000W to 9,000W for thermal design power for its next-generation GPUs, but experts from KAIST, a leading Korean research institute, believe that the TDP of AI GPUs will increase all the way to 15,360W over the next 10 years. As a result, they will require rather extreme cooling methods, including immersion cooling and even embedded cooling.
Until recently, high-performance air-cooling systems, which involved copper radiators and high-pressure fans, were sufficient to cool Nvidia's H100 AI processors. However, as Nvidia's Blackwell increased its heat dissipation to 1,200W and then Blackwell Ultra increased its TDP to 1,400W, liquid cooling solutions became almost mandatory. Things are going hotter with Rubin, which will increase its TDP to 1,800W, and with Rubin Ultra, which will double the number of GPU chiplets and HBM modules, along with a TDP that will go all the way to 3,600W. Researchers from KAIST believe that Nvidia and its partners will use direct-to-chip (D2C) liquid cooling with Rubin Ultra, but with Feynman, they will have to use something more powerful.
Expected heat dissipation of AI GPUs, according to KAIST and industry sources
Swipe to scroll horizontally
Generation | Year | Total Power of GPU package | Cooling Method |
Blackwell Ultra | 2025 | 1,400W | D2C |
Rubin | 2026 | 1,800W | D2C |
Rubin Ultra | 2027 | 3,600W | D2C |
Feynman | 2028 | 4,400W | Immersion Cooling |
Feynman Ultra | 2029 | 6,000W* | Immersion Cooling |
Post-Feynman | 2030 | 5,920W | Immersion Cooling |
Post-Feynman Ultra | 2031 | 9,000W* | Immersion Cooling |
? | 2032 | 15,360W | Embedded Cooling |
*Industry source
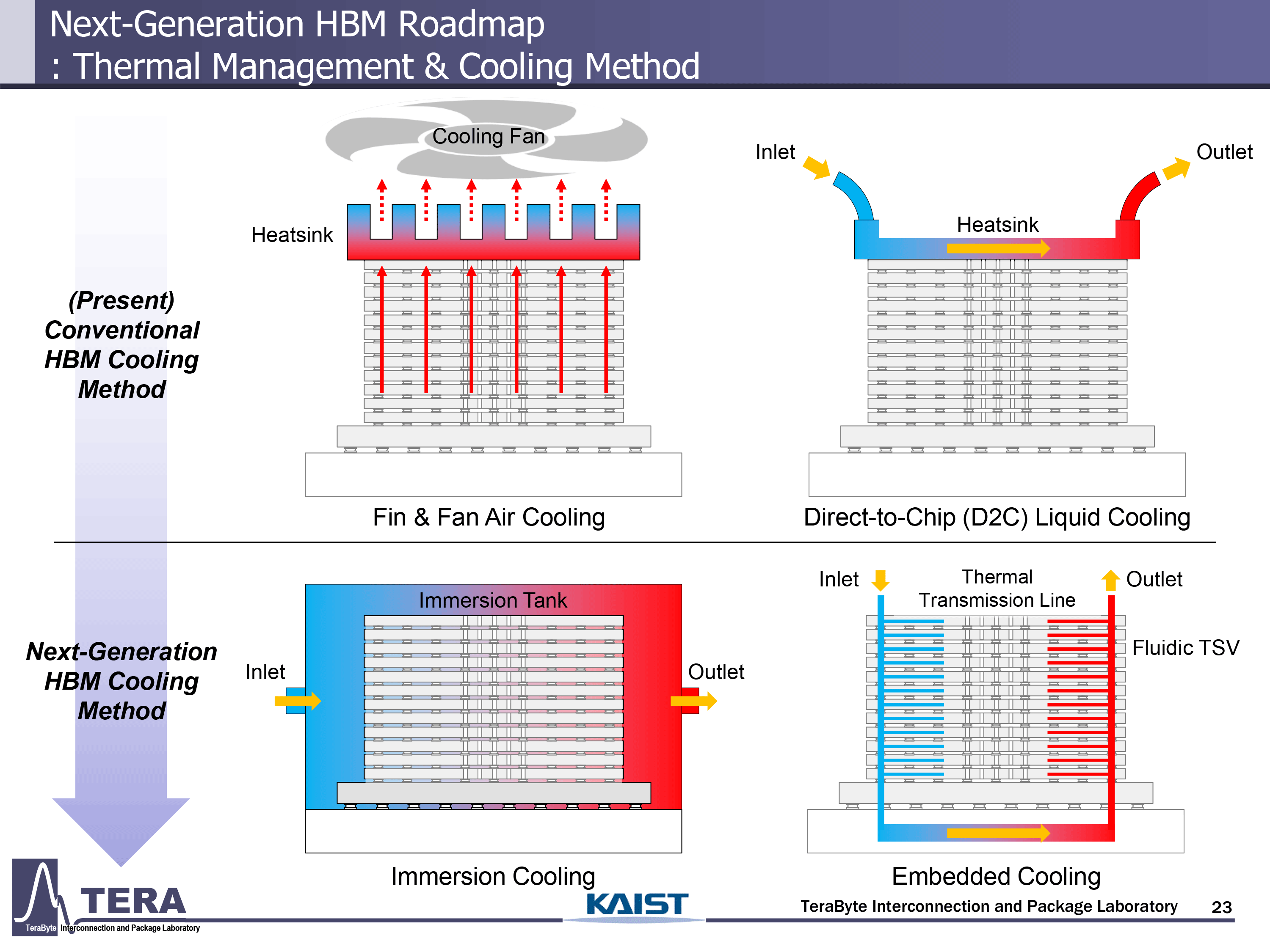
Researchers from KAIST predict that AI GPU modules (particularly Nvidia's Feynman) will dissipate 4,400W, whereas some other sources from the industry believe that Nvidia's Feynman Ultra will increase its TDP to 6,000W. Such extreme thermals will require the usage of immersion cooling, where entire GPU-HBM modules are submerged in a thermal fluid. In addition, such processors and their HBM modules are expected to be introduced through thermal vias (TTVs), vertical channels in the silicon substrate dedicated to heat dissipation. These will be paired with thermal bonding layers and temperature sensors embedded in the HBM module base die for real-time thermal monitoring and feedback control.
Immersion cooling is expected to be good enough till 2032, when post-Feynman GPU architectures will increase per-package TDP to 5,920W (post-Feynman) or even 9000W (post-Feynman Ultra).
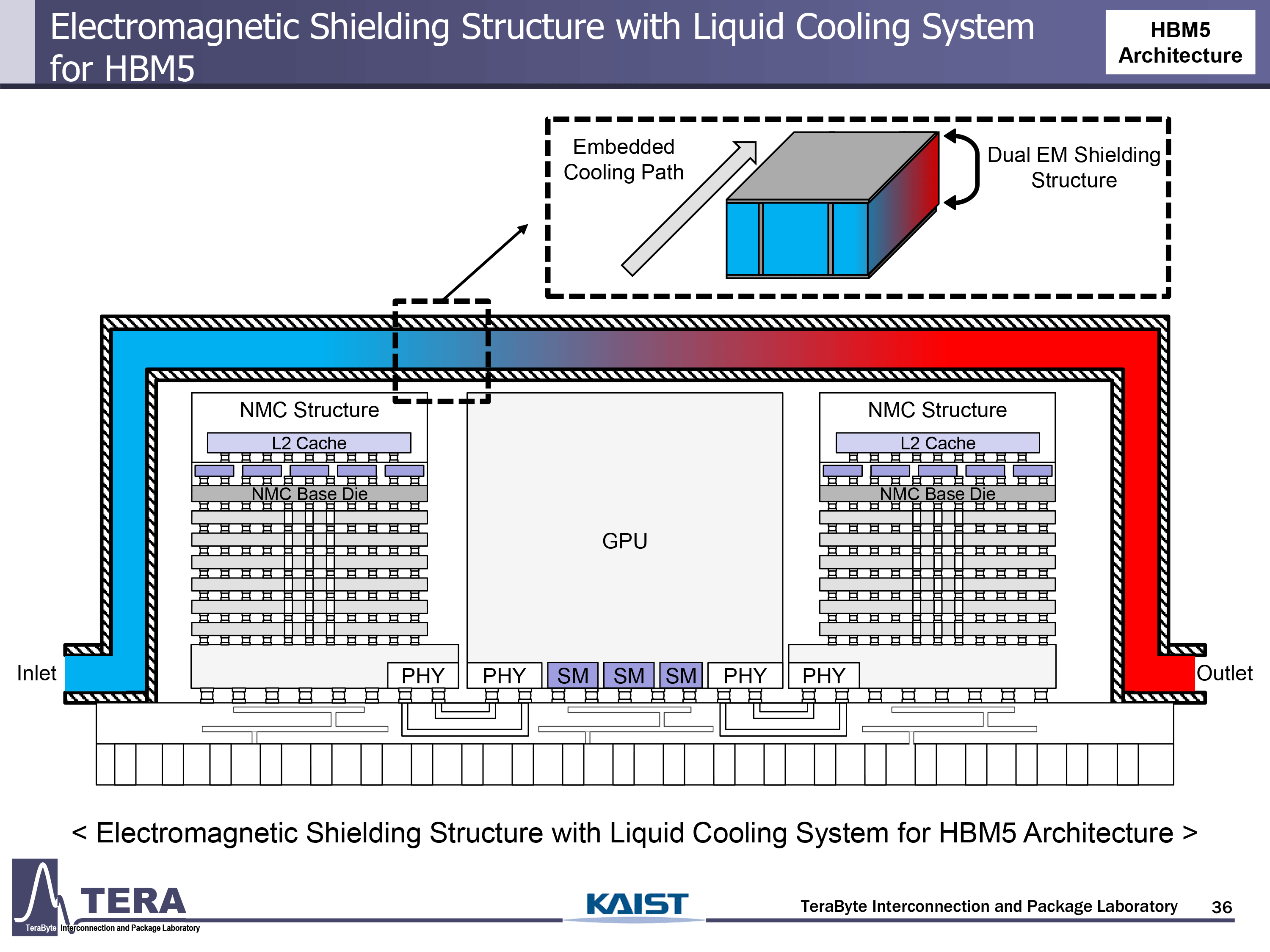
It is necessary to note that the main power consumers in a GPU module are compute chiplets. However, as the number of HBM stacks increases to 16 with post-Feynman, and per-stack power consumption increases to 120W with HBM6, the power consumption of memory will be around 2,000W, which is around 1/3 of the whole package.
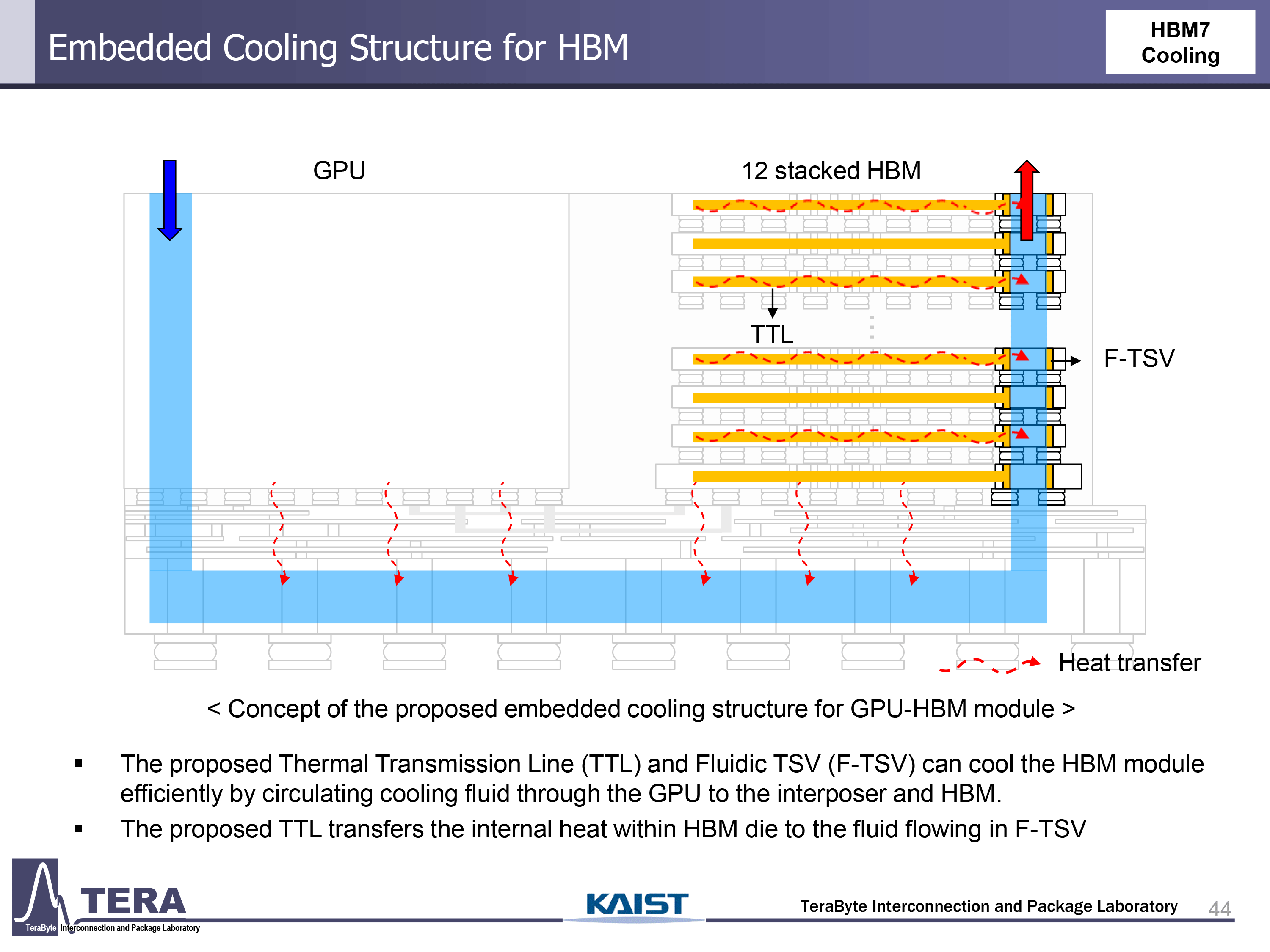
Researchers from KAIST theorize that by 2035 power consumption of AI GPUs will increase to around 15,360, which will call for embedded cooling structures both for compute and memory chiplets. The experts mention two key innovations: thermal transmission lines (TTLs) that move heat laterally from hotspots to cooling interfaces, and fluidic TSVs (F-TSVs) that allow coolant to flow vertically through the HBM stack. These methods are integrated directly into the interposer and silicon to maintain thermal stability.
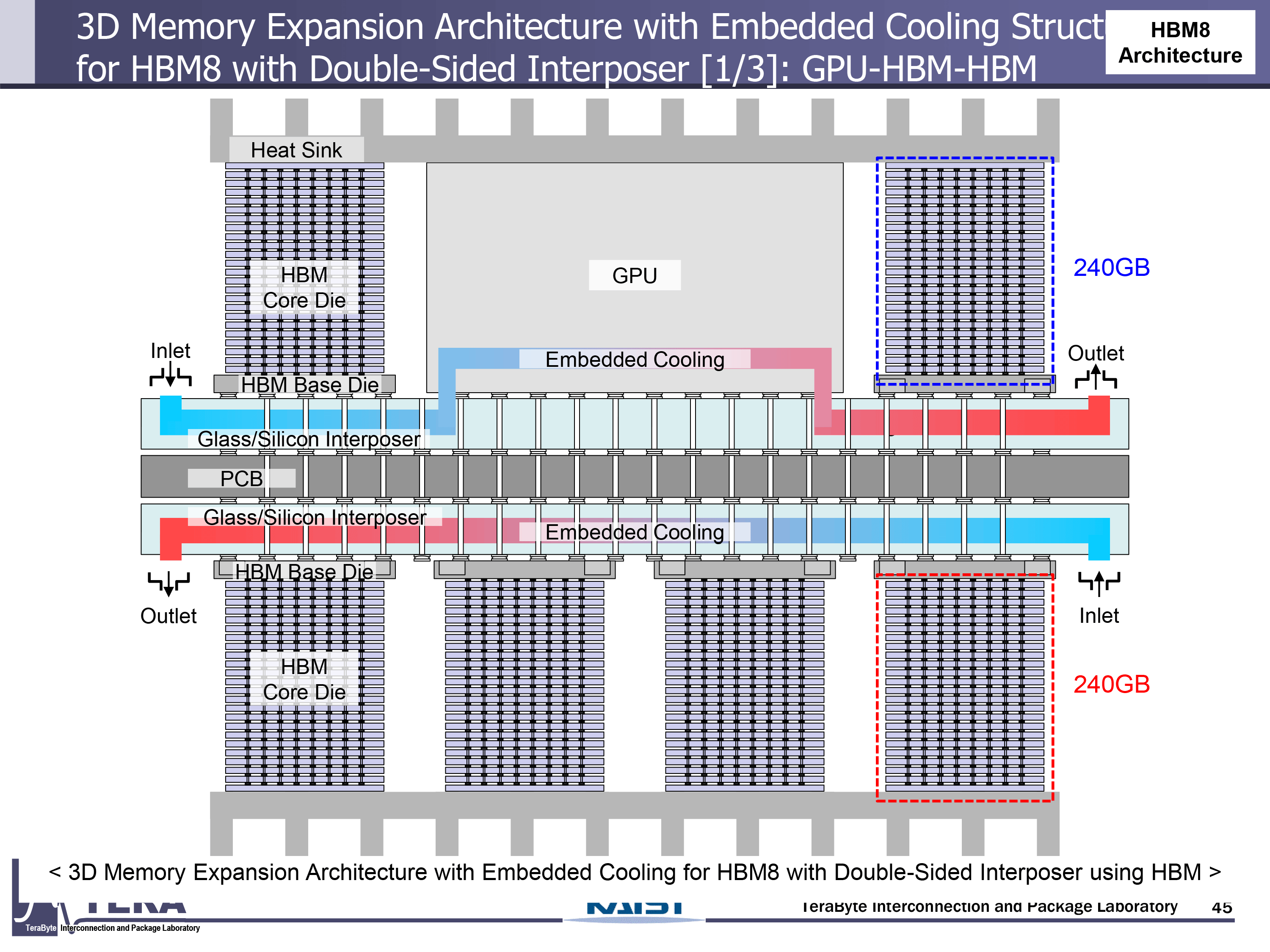
By 2038, fully integrated thermal solutions will get even more widespread and advanced. They will use double-sided interposers to enable vertical stacking on both sides, with fluidic cooling embedded throughout. Also, GPU-on-top architectures will help prioritize heat removal from the compute layer, while coaxial TSVs assist in balancing signal integrity and thermal flow.
Follow Tom's Hardware on Google News to get our up-to-date news, analysis, and reviews in your feeds. Make sure to click the Follow button.








 English (US) ·
English (US) ·