 5 months ago
21
5 months ago
21
inquiring artificial minds want to know
New studies reveal pattern-matching reality behind the AI industry's reasoning claims.
On Tuesday, OpenAI announced that o3-pro, a new version of its most capable simulated reasoning model, is now available to ChatGPT Pro and Team users, replacing o1-pro in the model picker. The company also reduced API pricing for o3-pro by 87 percent compared to o1-pro while cutting o3 prices by 80 percent. While "reasoning" is useful for some analytical tasks, new studies have posed fundamental questions about what the word actually means when applied to these AI systems.
We'll take a deeper look at "reasoning" in a minute, but first, let's examine what's new. While OpenAI originally launched o3 (non-pro) in April, the o3-pro model focuses on mathematics, science, and coding while adding new capabilities like web search, file analysis, image analysis, and Python execution. Since these tool integrations slow response times (longer than the already slow o1-pro), OpenAI recommends using the model for complex problems where accuracy matters more than speed. However, they do not necessarily confabulate less than "non-reasoning" AI models (they still introduce factual errors), which is a significant caveat when seeking accurate results.
Beyond the reported performance improvements, OpenAI announced a substantial price reduction for developers. O3-pro costs $20 per million input tokens and $80 per million output tokens in the API, making it 87 percent cheaper than o1-pro. The company also reduced the price of the standard o3 model by 80 percent.
These reductions address one of the main concerns with reasoning models—their high cost compared to standard models. The original o1 cost $15 per million input tokens and $60 per million output tokens, while o3-mini cost $1.10 per million input tokens and $4.40 per million output tokens.
Why use o3-pro?
Unlike general-purpose models like GPT-4o that prioritize speed, broad knowledge, and making users feel good about themselves, o3-pro uses a chain-of-thought simulated reasoning process to devote more output tokens toward working through complex problems, making it generally better for technical challenges that require deeper analysis. But it's still not perfect.
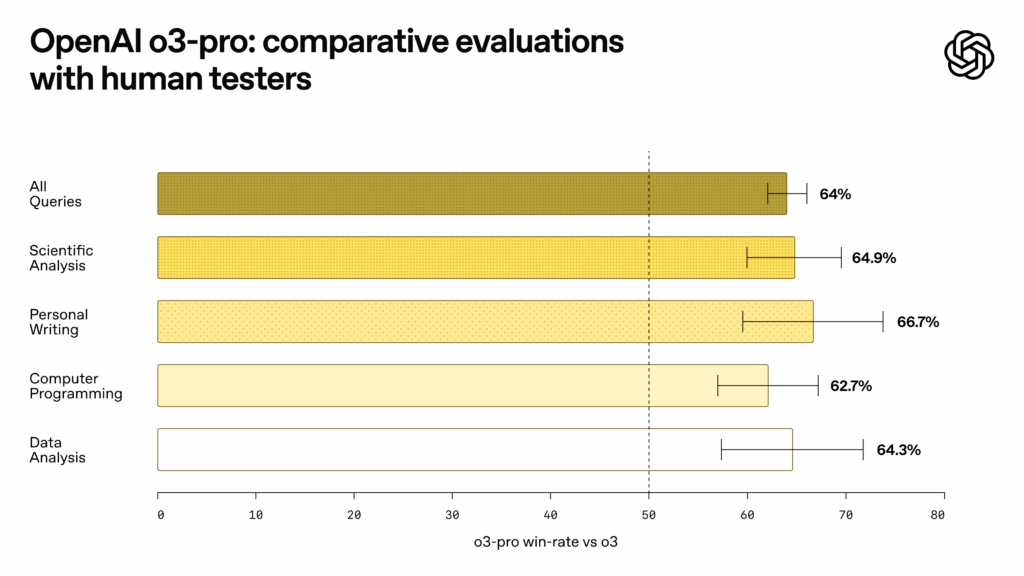
An OpenAI's o3-pro benchmark chart. Credit: OpenAI
Measuring so-called "reasoning" capability is tricky since benchmarks can be easy to game by cherry-picking or training data contamination, but OpenAI reports that o3-pro is popular among testers, at least. "In expert evaluations, reviewers consistently prefer o3-pro over o3 in every tested category and especially in key domains like science, education, programming, business, and writing help," writes OpenAI in its release notes. "Reviewers also rated o3-pro consistently higher for clarity, comprehensiveness, instruction-following, and accuracy."
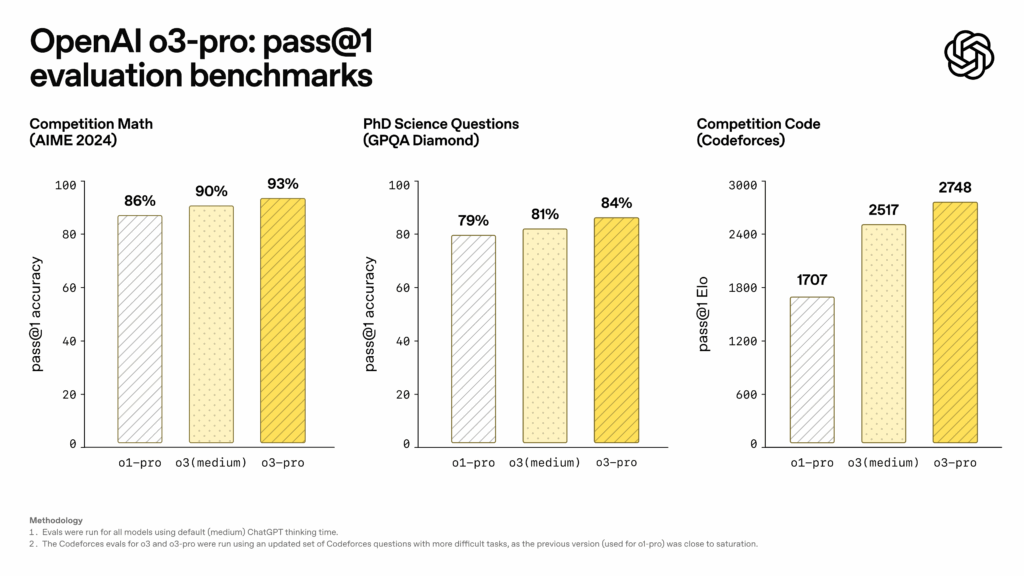
An OpenAI's o3-pro benchmark chart. Credit: OpenAI
OpenAI shared benchmark results showing o3-pro's reported performance improvements. On the AIME 2024 mathematics competition, o3-pro achieved 93 percent pass@1 accuracy, compared to 90 percent for o3 (medium) and 86 percent for o1-pro. The model reached 84 percent on PhD-level science questions from GPQA Diamond, up from 81 percent for o3 (medium) and 79 percent for o1-pro. For programming tasks measured by Codeforces, o3-pro achieved an Elo rating of 2748, surpassing o3 (medium) at 2517 and o1-pro at 1707.
When reasoning is simulated

It's easy for laypeople to be thrown off by the anthropomorphic claims of "reasoning" in AI models. In this case, as with the borrowed anthropomorphic term "hallucinations," "reasoning" has become a term of art in the AI industry that basically means "devoting more compute time to solving a problem." It does not necessarily mean the AI models systematically apply logic or possess the ability to construct solutions to truly novel problems. This is why Ars Technica continues to use the term "simulated reasoning" (SR) to describe these models. They are simulating a human-style reasoning process that does not necessarily produce the same results as human reasoning when faced with novel challenges.
While simulated reasoning models like o3-pro often show measurable improvements over general-purpose models on analytical tasks, research suggests these gains come from allocating more computational resources to traverse their neural networks in smaller, more directed steps. The answer lies in what researchers call "inference-time compute" scaling. When these models use what are called "chain-of-thought" techniques, they dedicate more computational resources to exploring connections between concepts in their neural network data.
During the "reasoning" process, the AI model outputs a stream of text where it "thinks out loud," so to speak, using tokens of output to ostensibly work through problems step-by-step in a way that's visible to users, unlike traditional models that jump directly to an answer.
Each intermediate "reasoning" output step (produced in tokens) serves as context for the next token prediction, effectively constraining the model's outputs in ways that tend to improve accuracy and reduce mathematical errors (though not necessarily factual ones).
But fundamentally, all Transformer-based AI models are pattern-matching marvels. They borrow reasoning patterns from examples in the training data that researchers use to create them. Recent studies on Math Olympiad problems reveal that SR models still function as sophisticated pattern-matching machines—they cannot catch their own mistakes or adjust failing approaches, often producing confidently incorrect solutions without any "awareness" of errors.
Apple researchers found similar limitations when testing SR models on controlled puzzle environments. Even when provided explicit algorithms for solving puzzles like Tower of Hanoi, the models failed to execute them correctly—suggesting their process relies on pattern matching from training data rather than logical reasoning. As problem complexity increased, these models showed a "counterintuitive scaling limit," reducing their reasoning effort despite having adequate computational resources. This aligns with the USAMO findings showing that models made basic logical errors and continued with flawed approaches even when generating contradictory results.
However, there's some serious nuance here that you may miss if you're reaching quickly for a pro-AI or anti-AI take. Pattern-matching and reasoning aren't necessarily mutually exclusive. Since it's difficult to mechanically define human reasoning at a fundamental level, we can't definitively say whether sophisticated pattern-matching is categorically different from "genuine" reasoning or just a different implementation of similar underlying processes. The Tower of Hanoi failures are compelling evidence of current limitations, but they don't resolve the deeper philosophical question of what reasoning actually is.

And understanding these limitations doesn't diminish the genuine utility of SR models. For many real-world applications—debugging code, solving math problems, or analyzing structured data—pattern matching from vast training sets is enough to be useful. But as we consider the industry's stated trajectory toward artificial general intelligence and even superintelligence, the evidence so far suggests that simply scaling up current approaches or adding more "thinking" tokens may not bridge the gap between statistical pattern recognition and what might be called generalist algorithmic reasoning.
But the technology is evolving rapidly, and new approaches are already being developed to address those shortcomings. For example, self-consistency sampling allows models to generate multiple solution paths and check for agreement, while self-critique prompts attempt to make models evaluate their own outputs for errors. Tool augmentation represents another useful direction already used by o3-pro and other ChatGPT models—by connecting LLMs to calculators, symbolic math engines, or formal verification systems, researchers can compensate for some of the models' computational weaknesses. These methods show promise, though they don't yet fully address the fundamental pattern-matching nature of current systems.
For now, o3-pro is a better, cheaper version of what OpenAI previously provided. It's good at solving familiar problems, struggles with truly new ones, and still makes confident mistakes. If you understand its limitations, it can be a powerful tool, but always double-check the results.

Benj Edwards is Ars Technica's Senior AI Reporter and founder of the site's dedicated AI beat in 2022. He's also a tech historian with almost two decades of experience. In his free time, he writes and records music, collects vintage computers, and enjoys nature. He lives in Raleigh, NC.









 English (US) ·
English (US) ·